When most engineering teams talk about "using AI in development," they mean a developer has GitHub Copilot installed. Suggestions appear as they type. Some are useful, some aren't. The developer accepts what looks right and moves on.
That's AI-assisted coding. It's useful. It's also only one small piece of what AI-driven development actually is — and conflating the two is one of the most common mistakes teams make when trying to modernize their delivery process.
An AI coding assistant operates at the level of a single engineer writing a single file. It autocompletes functions, suggests variable names, and sometimes generates a block of boilerplate. The engineer is still responsible for every decision — the tool just types faster.
An AI-driven development environment operates at the level of the entire delivery system. It changes how work is specified, how it's designed, how it's tested, how it's deployed, and how production health is monitored. The engineer's role shifts from authoring every line to reviewing, validating, and directing AI-generated output within a system designed to catch problems automatically.
If your team is currently using AI coding tools without this surrounding infrastructure, you have the first piece of a much larger system. The tools are not wrong — the context they're operating in is incomplete.
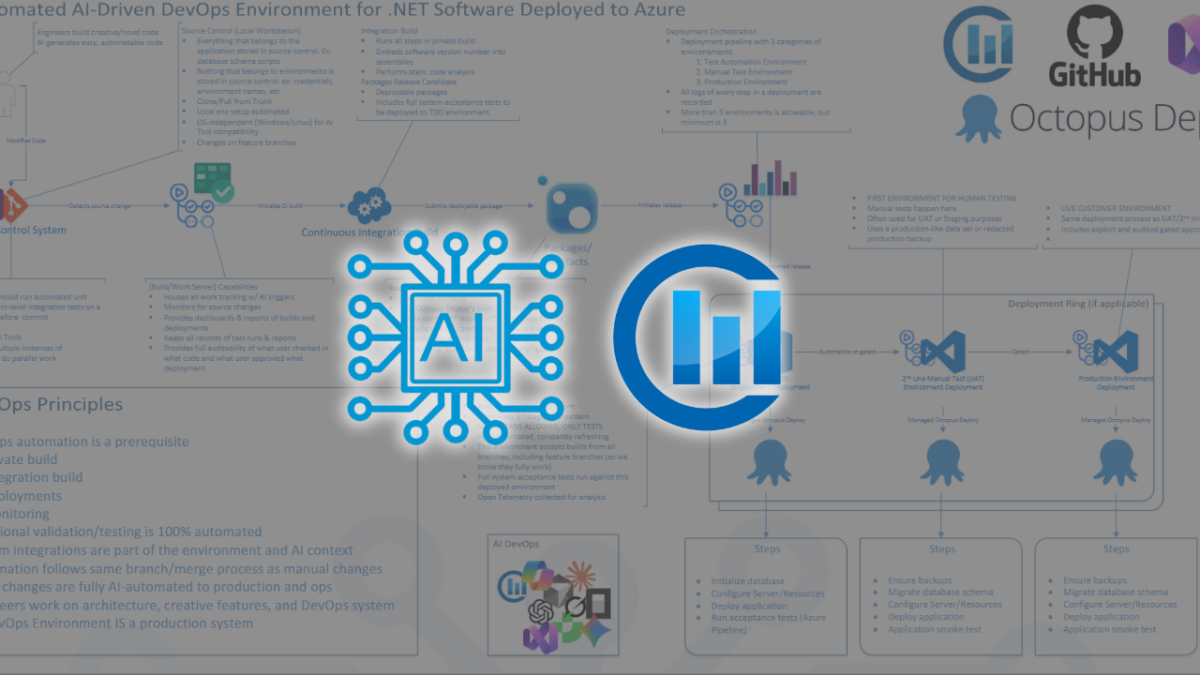
The good news is that building the system is a structured process. It starts with establishing a consistent architectural foundation, adds automated quality gates and pipeline hardening, and then layers in AI-assisted generation on top of an environment designed to validate and deploy that output safely.
The distinction between AI-assisted coding and AI-driven development isn't academic. It's the difference between a tool that speeds up one engineer and a system that transforms how an entire team delivers software. Understanding where you are on that spectrum is the first step toward building something better.
AI-Assisted Coding
Autocompletes code inside the IDE. Speeds up authoring. The delivery system around it is unchanged — manual processes, manual testing, manual deployment.AI-Driven Development
Automates requirements, design, code generation, testing, CI/CD, UAT, and production monitoring. The entire delivery system is built to support and validate AI-generated output.
"A coding assistant accelerates one engineer writing one file. An AI-driven development environment automates the system of delivering software."
According to GitHub's 2024 State of the Octoverse, 97% of developers now use AI coding tools in some capacity. Adoption has become the norm. But adoption alone doesn't produce the results teams expect — and in many cases, it makes things worse.
When AI coding tools are dropped into an existing delivery process without changing the system around them, the results are predictable:
- Generated code reflects the inconsistencies of the existing codebase — at higher volume and faster pace
- Defects that would have taken a human time to introduce now appear in bulk
- Velocity increases short-term while technical debt accumulates invisibly
- The codebase becomes harder to maintain, not easier
Structured checklist templates and AI-generated specs replace unstructured discovery sessions. Analysts produce precise, machine-readable requirements that feed directly into technical design — no translation layer, no information lost.
Architecture patterns decompose requirements into development tasks automatically. Design becomes repeatable rather than ad hoc — every feature follows the same structural logic, which is exactly what makes AI code generation reliable downstream.
LLMs generate implementation code and test scenarios directly from design specs. Engineers review, validate, and extend — they are no longer authoring from scratch. The quality of this output depends entirely on the quality of phases 1 and 2 feeding into it.
Fully automated pipelines handle build, multi-level testing, environment provisioning, UAT promotion, and production deployment. Every change — regardless of how fast it was generated — moves through the same quality gates before it reaches a customer.
Telemetry is analyzed on a defined cadence — hourly, daily, weekly. AI surfaces anomalies and generates improvement suggestions automatically. The system doesn't just deliver software; it watches what happens after delivery and feeds that signal back into the process.
Want the Full Framework?
Clear Measure's AI-driven development methodology covers the complete lifecycle — from readiness assessment and architectural standardization through full pipeline automation and production telemetry. See the full technical guide →
Talk to a Clear Measure AI DevOps Architect. We'll assess your codebase, DevOps foundation, and delivery baseline and tell you honestly what your AI readiness looks like.
Talk to an Architect