
In the world of message-based systems, asynchronous messaging in a distributed system is great! It allows clients to move on with their lives without waiting on a response from the service. It can also enable sending messages when the service is unavailable, and help create a more predictable load. However, async messaging has its downsides as well. It adds overhead to individual requests and unpredictable traffic could theoretically cause this service to grow its queue indefinitely.
Let’s assume in the following diagram that there are 4 clients and each client sends 2 messages per second to FooService. While FooService can process up to 4 messages per second.

Clearly, this will become a problem if the traffic continues at this rate. Processing times on newly sent messages will grow quickly while the queue will consume more and more memory. There are a few solutions to this problem, one of which is to add an additional FooService to read from the queue, or you could utilize some strategies of backpressure.
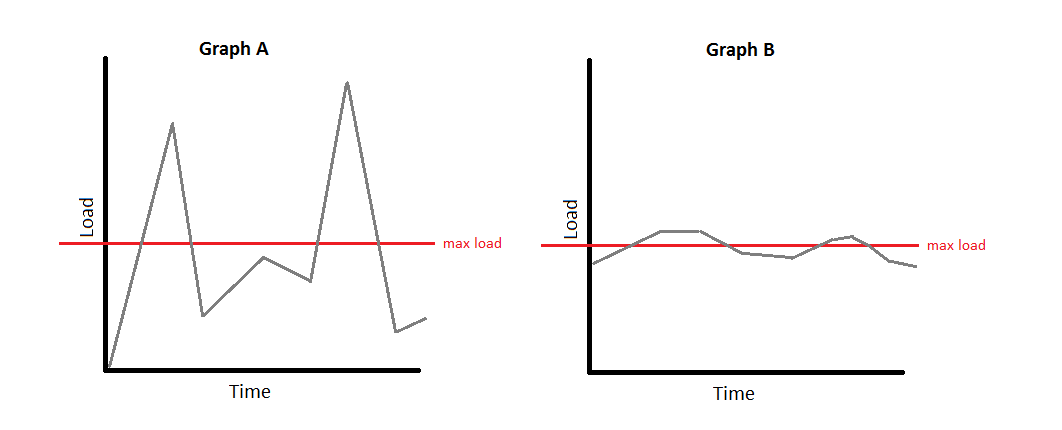
Note: I would like to preface these strategies with the caveat that the growing queue problem can and should be solved by improving/adding hardware or optimizing the service in most cases. You may want to consider one of these methods when adding hardware is not an option and your traffic looks more like graph A than graph B.
Replacing the call with a synchronous one enables FooService to put pressure back on the clients in order to regulate its traffic. Each client will be blocked while waiting for their message to be processed, preventing them from sending any other messages. Sounds bad right? However, this means that the work queue cannot have any more messages in it than the number of clients utilizing the service. In this case, 4.

Each client will now have to wait at most 1 second for its request to finish processing. This limits the work Foo will need to do while also maintaining a consistent response time for each client.
There are a few things to keep in mind with this approach.
Keep synchronous processing in mind if you can afford to push the time back to your clients and consistent time in message processing is necessary.
For example, you have web clients that need their request processed before they can proceed on the website, maybe some kind of legal disclosure, but you want to maintain message persistence. This will enable your system to maintain message durability and limit the queue size.
Synchronicity is not the only way to handle out-of-control queues. Perhaps an even simpler solution is to have a limit on your queues and drop messages that are added over the limit. Obviously, you must be ok with losing a certain percentage of messages during high load, but this will allow clients to keep the fire and forget mentality and protect your service from being overwhelmed.

The message loss can be mitigated by storing the dropped messages elsewhere or retrying with an exponential backoff strategy. Load shedding is a great way to maintain responsiveness on clients and control load as long as some message loss is acceptable.
For example, you have a device with limited memory and only cares about the latest data, like a small weather station. It could receive updates from many different sources but we really only care about the current data. So a good strategy could be to drop the oldest messages from the queue.
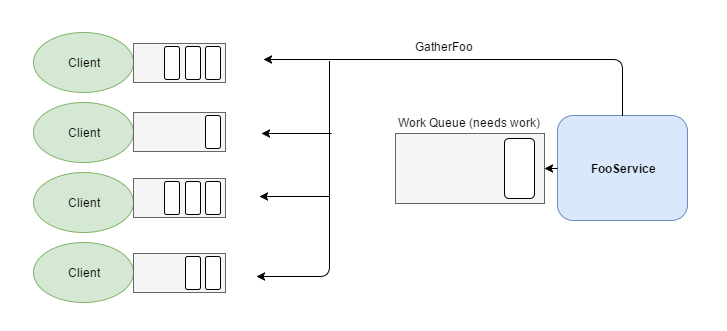
Instead of pushing work to the FooService, why don’t we have it request work from the clients when it is ready? The basic idea of this is to push the message storing/queueing onto the clients while the work queue for FooService stays at an acceptable level. A simple way to do this is to publish an event, e.g. GatherFoo, from FooService when its work is low. GatherFoo is then consumed by the clients, which can offload some of their outbound queue onto the work queue.
FooService requests work by publishing GatherFoo.
Clients send messages from their outbound queue to FooService.
The main benefit of this strategy is to spread the responsibility of storage across the system while limiting load. A downside is that the service now has to make two round trips to process one message, which will add latency to the request.
For example, you have a website that only wants to process requests while the client is connected, and if the client unsubscribes from the event or disconnects they remove their pending work from needing to be processed.
Hopefully, now you have an idea of strategies to consider when dealing with bursts of traffic in your system. These are not the only ways to solve the overflowing queue problem. Adding hardware and optimizing your services should be your go-to strategy, but it does not hurt to have these in your development playbook.