
This post will show you the benefit of a centralized logging solution.
Your team has been working hard eight hours a day shipping new features, and you’re super proud of the work everyone is putting out – work items are dropping of the backlog in droves! But suddenly, you get a ping from Slack – your customers are occasionally getting an error page. And it’s in a part of the system that rarely gets touched. In fact, it’s in a part of the system that hasn’t been changed in months, so you’re at a loss for what may be happening.
That’s okay, you have the code on your machine, right? Just follow the repro steps against your local instance and see if you can reproduce it! …but it doesn’t, in fact, it seems like its working fine.
When the vague repro steps from your users aren’t enough to figure out what’s going on in a complicated system, things can get really messy. What if it’s an occasional hardware issue? Or a race condition that only happens under load? Maybe it’s a third-party service that only runs in production, or even a series of steps a user took prior to getting to this screen that even they didn’t realize was related to the issue.
For debugging messy issues like this one, we commonly recommend taking advantage of some sort of centralized logging. After all, you can’t just connect your Visual Studio debugger to production, it’s way too invasive. And even if you could, with repro steps that may or may not work every single time, it may be hours or days until the issue comes back.
A centralized logging solution connects the various pieces of your software into a single, unified, searchable log that accumulates details about every aspect of your system in near real-time. This allows you to piece together traits about how your software is running all in one place. And what’s great is that most of them work with off-the-shelf logging libraries, so all you need to worry about is hooking them up and then adding some log messages to your code.
Take a look at Azure ApplicationInsights, SumoLogic, or Stackify, for a full look of the feature set. Each of them varies a bit in what they can do – but all of them allow you to have a unified way of searching across all the logs in your entire system to hunt for errors, slow response times, or even obscure chains of transactions that can be analyzed for timings, failure rate, duplication, or other potential flows that are harder to see when you view one log file at a time. They even allow you to install an agent on your servers to collect non-application data like Windows Event Logs, web server logs, or any text file type that – you can then correlate those events with your own application logs and find really obscure trends.
Many can even help you create searches that are plotted to various types of graphs, allowing you to create complex dashboards of real-time trends for your application’s set of goals. Take a look at the example below for a dashboard we use for monitoring traffic on a large public-facing system:

We like SumoLogic in particular with the ability to perform very detailed queries over patterns of completely disconnected data sets. For instance, the below query looks for one handler where a message is being sent to an external provider, and then looks for another log message indicating a response was received from the external provider. It then correlates them together by the MessageId, to determine the time it took the third party to get us a response. Finally, it takes the entire dataset and slices it into time-buckets, allowing us to generate an average and max dimension for this complicated search over time.

You can then turn the dataset into a graph to get more details about the timings of peaks and lulls in the data, and use that to build a quick custom search for a specific time range so you can find out what may have caused an issue. As shown below, the external provider seems to have taken 33 seconds to respond to a particular message around 10am, but it wasn’t a widespread issue as the average only ticked up slightly around that time.

You are also able to do some powerful 24/7 alerting just by adding conditions to search for. For instance, if your application gathers more than 10 errors over a 15 minute period, you may want it to send you an email. If it’s 30 errors in that same time, you may want it to ping your team’s slack channel. If it’s 100 errors, it may be time to page some who is on call to jump right on immediately.
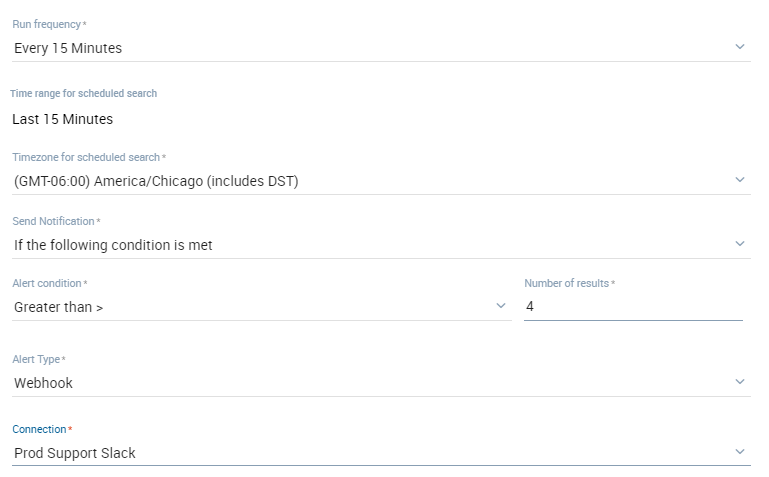
You can also set alerts for things you expect to happen, but aren’t happening. For instance, if you’re expecting a third party service to call you at least 10 times a minute to send you a batch of transactions, you may want to get an alert if process suddenly stops and thus your typical log messages aren’t getting logged. In SumoLogic, you can just change the Alert Condition to “Less Than” and some minimal threshold that won’t alert unless there is truly an issue to be concerned about.
You can’t search on logs your code isn’t emitting! So we consider it a best practice to add logging to your code as you’re making changes. A good baseline is to always log entrances, exits, and any try/catches of your primary modules, and to log as many parameters sent to that function as is feasible, excluding of course personally identifiable data (PII). The most important parameters to log are things like the Primary Keys of the entity being worked on and any extra parameters, such as boolean flags or enums, that make that item’s processing unique. This will ensure that down the line, when you suddenly need to investigate something in a hurry, there is a high likelihood you can find the patterns you need without making changes and doing a deploy.

In the above ASP.NET MVC Controller example, we create a shared log message as a string called msg which will serve as the searchable marker for this transaction in our unified logger. In the searchable marker, we normally include the name of the method we’re in, any any commonly used details of this transaction – in this case, the ObjectTypeName that was requested. We also kick off a stopwatch to time our progress from the beginning of the transaction to the end. We log our entrance to the method with “ENTER”, then do our work as normal. In the catchphrase, we log the word “ERROR” with the same searchable marker (msg) and send along the exception to our logging provider. This sends a full stack trace to our logger, so once we find an error, we can deep dive into where it was and what error message/error code accompanied it. If we make it all through the complex work without throwing an exception, we log our “EXIT” along with the searchable marker again. Inside the “EXIT” and “ERROR” cases, we also include a stopwatch in milliseconds so we can determine if there were any substantive delays in processing this request. This gives us an easy way to create performance graphs without some of the more complex queries demonstrated above.
Most central logging providers out there also support “structured logging” – the ability to log formatted data such as JSON or XML. Setting your log stream as structured gives added search benefits as you can do some really advanced filtering of your log data at the expense of readability. For instance, if you need to find every request where the MaxPageSize was greater than 70, you can write a query out to find them all very easily. Just be aware, however, that the ability to quickly scan logs with your eyes to find patterns might be lost, as you’d then need to expand each row of data in order to see in the result set to see the full context around what happened.
By having your team stay in the habit of logging as you go, and by utilizing centralized logging and the various features within each of those central logging providers, you’re able to keep up with issues in your production environment a lot easier than blindly debugging things as they happen. The time you take logging today could save you hours of grasping at straws in the future.
If you want further help getting your team caught up on this or other DevOps processes, reach out to us! We have a team of passionate engineers that enjoy spreading the joy of efficient, smooth running DevOps processes. We can help you get your team on the right track to help you minimize downtime, or at least, minimize how long it takes to resolve an issue that pops up at an inopportune time.